Wertschöpfung mit Big Data
Den Wert der Daten korrelieren
„We are drowning in information but starved for knowledge.“ Der im Jahr 1982 von John Naisbitt formulierte Satz hat noch nie so zugetroffen wie heute. Im Zeitalter digital gestützter Produktionssysteme rücken nun verstärkt Technologien und Konzepte in den Vordergrund, um nützliche Informationen aus stetig steigenen Datenmengen zu gewinnen. Dieser Beitrag liefert Einblicke in den potenziellen Nutzen und Ansätze im Umgang mit Big Data.
")
Die Datenproduktion steigt zunehmend und das in allen Lebens- und Industriebereichen. So wird vermutet, dass die globale Datenproduktion im Jahr 2020 44-fach höher sein wird als sie es im Jahr 2009 war. In Zahlen ausgedrückt könnte das Volumen von 0,79 Zetabyte auf rund 35 Zetabyte ansteigen. Neben der Sammlung der Daten stellen vor allem die Speicherung und die sinnvolle Nutzung große Herausforderungen dar. Schätzungen zufolge bleiben etwa 70 Prozent der erfassten Fertigungsdaten, oftmals als Dark Data bezeichnet, ungenutzt. IBM geht sogar davon aus, das ungenutzte Sensordaten für einen Dark Data-Anteil in der Höhe von 90 Prozent sorgen.
Hohe Hürden für die Nutzung
Es gibt mehrere Herausforderungen im Umgang mit der Menge an Daten und ihrem Nutzungspotential. Die schier unendliche Menge an Daten (Big Data) stammt aus unterschiedlichen Quellen, die in Struktur und Komplexität die Heterogenität der Datenvielfalt erhöhen. Zusätzlich muss mit gelegentlichen Fehlern bei der Datenerfassung und -speicherung gerechnet werden, sodass Datensätze inkonsistent oder unvollständig sein können – was die Nutzung maßgeblich einschränkt. Zudem ist es von Bedeutung, wann die Daten in welcher Form benötigt werden. Sollen die Daten etwa zur adaptiven Prozesssteuerung genutzt werden, müssen sie dem Datenmodell latenzarm zur Verfügung gestellt werden, um rechtzeitige Eingriffe in den Prozess oder Regelkreis zu erlauben.
Nicht jeder ist Data Scientist
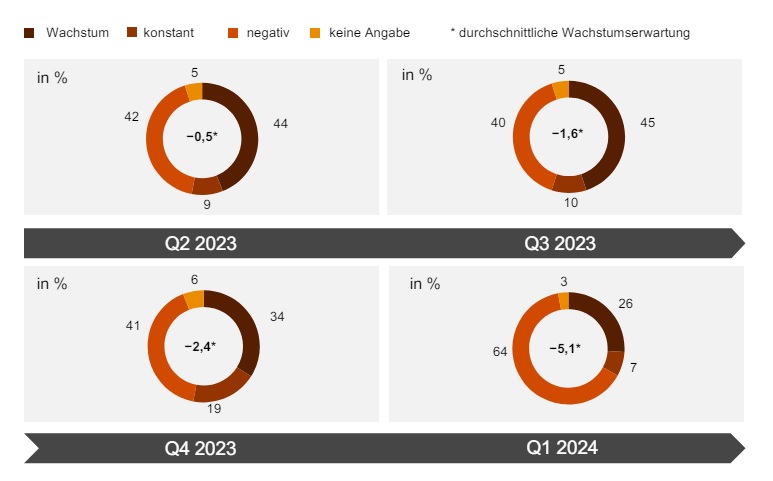
Neben der Frage der Datensicherheit und -verantwortung stellt die Visualisierung und Ergebnisdarstellung großer heterogener Datenmengen eine weitere Herausforderung dar, da nicht jeder Datennutzer gleichzeitig auch ein Data Scientist ist. Angesichts der aktuellen technischen Möglichkeiten stellt sich die Frage nach der Sinnhaftigkeit des Big Data-Trends. Sind Anwender überhaupt schon bereit, so viele Daten zu erfassen? Oder sollten sie nur mit konkretem Ziel gesammelt werden? In den Diskussionen um diesen Sachverhalt wird häufig der Begriff Smart Data benutzt, der sich wiederum unterschiedlich definieren lässt. Zum einen bedeutet Smart Data, aus großen chaotischen Datenmengen, durch Einbringen von Semantik und Struktur, die informationstragenden Datensätze herauszufiltern. Es kann aber auch als kausalgetriebene Herangehensweise gesehen werden, bei der nur die Daten gesammelt werden, die man zum Beantworten einer konkreten Frage braucht. Unabhängig von der Definition bietet der Ansatz der Smart Data einen sinnvollen Zwischenschritt, um die Potentiale von Daten nutzen zu können. Potentiale finden sich in allen Unternehmensbereichen entlang des Produktlebenszyklus: Als Beispiele können die Unterstützung von Make-or-Buy-Entscheidungen, Analyse und Vorhersage vom Kundenbedarf, das Aufdecken unbekannter Zusammenhänge in Datensätzen (Data Discovery) oder die vorausschauende Planung und Wartung von Produktionsanlagen und Ressourcen (Predictive Maintenance/Process Control) genannt werden. Analog zum Produktlebenszyklus, der seinen Anfang in der Idee und Konstruktion des Produktes hat, durchlaufen Daten einen Lebenszyklus, der in der Auswahl und Erfassung der Daten, also den Datenquellen seinen Anfang findet. Die neunte Ausgabe von Rockwell Automations „State of Smart Manufacturing“ Report liefert Einblicke in Trends und Herausforderungen für Hersteller. Dazu wurden über 1.500 Fertigungsunternehmen befragt, knapp 100 der befragten Unternehmen kommen aus Deutschland. ‣ weiterlesen
KI in Fertigungsbranche vorn
Unterschiedliche Datenquellen
Informationsträchtige Daten entstehen oft im Prozess, also in Maschinen und Sensoren. Jedoch liegen die Daten meist in heterogener Rohform, die ohne Bezug zum Prozess, Produkt oder den Anforderungen nicht ohne Weiteres verarbeitet werden können. Ausgenommen sind solche Sensordaten, die normalerweise in Regelungen entweder sofort verarbeitet oder durch Steuerungen einer Prozessleitebene zur langfristigeren Nutzung zur Verfügung gestellt werden. Aufgrund der vielen verschiedenen Maschinen, Maschinensteuerung und Sensoren, herrscht eine große Heterogenität der Datenquellen und damit der Datenformate. Dies ist hinsichtlich Semantik und Syntax eine große Herausforderung, da die Informationszusammenführung nicht oder nur unvollständig möglich ist. Initiativen wie die OPC Foundation versuchen zwar, industrieübergreifende Standards zu entwickeln, doch viele Unternehmen sind im Produktionsalltag weit von einer homogenen Systemlandschaft entfernt. Hauptursache für diese Situation ist ein bislang in vielen Unternehmen noch zu sehr vernachlässigtes Thema: Das Speichern, Verwalten und Bereitstellen von Daten. Erst das effiziente Speichern von Daten und die Aufbereitung dieser anfallenden Datenmengen ermöglichen es, Potenziale auszuschöpfen.

Data Warehouse und Data Lakes
Um alle benötigten Informationen verfügbar zu haben, müssen schnell auftretende, große und heterogene Datenmengen verarbeitet werden. Außerdem sind bestehende Daten zu integrieren und, verbunden mit neuen Daten, dem Anwender bedarfsgerecht zur Verfügung zu stellen. Klassische Konzepte, wie Data-Warehouse-Systeme, können Daten strukturiert zur Verfügung stellen. Die Daten werden hierfür zunächst aus der Datenquelle extrahiert, in das Schema des Data Warehouse-Systems transformiert und anschließend hineingeladen. Das Schema legt hierbei fest, welche Arten von Daten es geben kann, welche Bedingungen sie erfüllen müssen und in welchen Beziehungen sie zueinander stehen können. Für jedes abzulegende Datenformat muss einzeln festgelegt werden, wie die Transformation in das gemeinsame Schema erfolgen soll. Wenn sehr viele und sehr unterschiedliche Daten aufgenommen werden sollen, stößt dieser Ansatz an Grenzen. Zum einen muss für jedes Datenformat die Transformation definiert werden, was schnell unwirtschaftlich wird. Zum anderen benötigt die Überführung großer Datenmengen in das Data Warehouse viel Zeit. Das System ist nicht in der Lage, viele heterogene Datenquellen ohne größeren Aufwand zu verarbeiten (Riess und Reimann 2015). Ein Data Lake ist ein System zur Datenhaltung, das in den meisten Fällen für den skalierbaren Einsatz bei großen Datenmengen ausgelegt wird (Ignacio Terrizzano, Peter Schwarz, Mary Roth, John E. Colino 2015). Dabei können Daten beliebiger Strukturen aufgenommen werden. Während bei klassischen Ansätzen die aufzunehmenden Daten zunächst an die Struktur der Datenbank angepasst werden müssen, werden die Daten bei einem Data Lake unverändert abgespeichert. So kann ein heterogenes Datenumfeld in einem einzigen System abgebildet werden. Dies gilt beispielsweise für kleinschrittige Sensordaten aus einer Maschine bis hin zu Geschäftsdaten aus ERP-Systemen. Zusätzlich ist die Überführung ganzer Datenverzeichnisse ins Data Lake möglich. Bei der Überführung findet keine semantische also bedeutungsmäßige Homogenisierung statt. Diese erfolgt erst dann, wenn ein Nutzer mittels einer Applikation entsprechende Anfragen an das System stellt. Die Leistungsfähigkeit des Systems wird somit entscheidend von der Auslegung der Applikation bestimmt.
Algorithmen gegen Menschen
Wie beschrieben stellen meist performante Applikationen Anfragen an das Datenmanagementsystem. Solche Applikationen können systemintegrierte Programme oder Data Analytics-Systeme sein, die neben der Analyse einen Teil der Datenverwaltung abdecken können. Die Data Analytics Suite IBM Watson hat es beispielsweise geschafft, zwei Menschen beim Quizspiel Jeopardy! zu schlagen, die zuvor Rekordsummen darin gewonnen hatten. In Social Media und im Konsumbereich sind Data Analytics Anwendungen nicht mehr wegzudenken. In den letzten Jahren lässt sich dieser Trend immer mehr in der produzierenden Industrie durch die Verwendung von Datenanalysen verzeichnen. Dabei ist die Expertise derer, die mit dem Produktionsprozess in Berührung stehen, diesen beispielsweise entwickeln, kontrollieren oder steuern, für die Interpretation der Ergebnisse und die Entwicklung einer Datenanalyse noch immer essentiell. Das Manufacturing Execution System (MES) HYDRA optimiert Produktionsprozesse für Fertigungsunternehmen, um Wettbewerbsvorteile zu erzielen. ‣ weiterlesen
MES-Integrator und 360-Grad-Partner für optimierte Fertigung

Abgestufte Analysevarianten
Grundsätzlich lassen sich bei einer Datenanalyse vier Reifegrade unterscheiden. In der simpelsten Form wird unter Verwendung von statistischen Mitteln von der sogenannten beschreibenden Analyse gesprochen, beziehungsweise der Frage nachgegangen, was im Produktionsprozess geschieht. Über diagnostische Analysen werden Ursachen für Vorkommnisse identifiziert und analysiert. Diese Informationen werden bestenfalls für prädiktive und präskriptive Analysen genutzt, um den Prozessverlauf und die Produktqualität vorherzusagen und rechtzeitig Handlungsempfehlungen geben zu können, sodass die Robustheit des Prozesses und damit der Produktqualität sichergestellt wird. Unabhängig von der Analyse muss in der Produktionstechnik die zu beantwortende Frage klar formuliert werden. Daher ist die Erfahrung des Anwenders mit den Prozessen gefragt. Für die Interpretation und Implementation der Ergebnisse braucht es Wissen zur Verwendbarkeit der Ergebnisse und deren Auswirkungen. Die blinde Implementierung von Ergebnissen aus Datenanalysen lassen per se keine Rückschlüsse auf die Ursachen zu.
Passende Algorithmen finden
Ob Datenanalysen mit Hilfe von Suiten oder programmieraffinen Data Scientists durchgeführt werden, und ob es maschinelles Lernen, künstliche Intelligenz oder Data Analytics genannt wird: Es gibt eine unübersichtliche Zahl an Algorithmen, die in Frage kommen. Welcher Algorithmus sich am besten auf die jeweilige Fragestellung anwenden lässt, lässt sich vorab nicht pauschal bestimmen. Meist ist sogar eine stufenweise Analyse und Kombination verschiedener Algorithmen mit teilweise niedriger Komplexität sehr effizient. Optimal wäre die Anwendung verschiedener Algorithmen mit dem Datensatz und eine anschließende Performanceanalyse und Vergleich der Ergebnisse. Dies ist jedoch ein aufwendiges Verfahren, vor allem wenn Echtzeitanwendungen eine sofortige Analyse und Handlung voraussetzen.
Machinelles Lernen
Speziell beim maschinellen Lernen gibt es durch die Unterscheidung von supervised und unsupervised learning, also überwachtes und unüberwachtes Lernen, eine Einschränkung. Die Analyse eines Datensatzes kann ebenfalls nach einem modellgetriebenen oder datengetriebenen Ansatz erfolgen. Beim ersteren muss zunächst ein physikalisches Modell des Prozesses entwickelt werden, bevor Daten analysiert werden. Beim letzteren hingegen werden zunächst Daten unstrukturiert analysiert und bei bestehenden Korrelationen weiterverarbeitet. Stellt sich eine Abhängigkeit heraus, basiert diese nicht auf einem physikalischen Modell, sondern lediglich auf Datenpunkten. So können unter Umständen nicht vermutete Abhängigkeiten gefunden werden. Unabhängig davon, ob ein datengetriebenes oder ein modellbasiertes Vorgehen gewählt wird, empfiehlt es sich bei der Durchführung am CRISP-DM als systematischen Standardprozess beim Thema Datenanalyse zu orientieren. Der aus sechs Phasen bestehende Prozess umschreibt das Vorgehen ausgehend von Klärung der Zielfragestellung bis hin zur Implementierung des Datenmodells im Prozess.
Strategische Ressource
Die Weiterentwicklung von Daten als reines Prozessergebnis hin zu einer strategischen Ressource und einem wertvollen Produkt, hat in Social Media schon lange stattgefunden und steht wohl auch der Produktionstechnik bevor. Dass Daten analog zu anderen Produkten ebenfalls einen Lebenslauf haben und verschiedene Phasen durchlaufen, ist demnach ebenfalls nachvollziehbar. Der Erfolg der Produkte ‚Daten‘ hängt wie von der effizienten und effektiven Nutzung derselben ab. Dafür müssen die Grundphasen Speichern, Aufbereiten und Bereitstellen von Daten beherrscht werden. Zurzeit werden in der Wissenschaft und Industrie verschiedene Ansätze entwickelt, um große Datenmengen effizient zu verarbeiten und die entsprechenden Big Data-Potenziale zu heben. Die Vernetzung über Plattformen und unterschiedliche Datenformate hinweg stellt eine große Herausforderung dar. Data Lake-Systeme bieten hier neue Möglichkeiten. Anwendungsfelder sind derzeit vor allem Fälle, bei denen die Art der später folgenden Analyse bei der Erfassung der Daten noch unklar ist. Die durch ein Datenmanagement-System zur Verfügung gestellten Daten können auf vielfältige Weise genutzt werden, um die bestehenden Produktionsprozesse zu verbessern. Bevor man Daten erfasst und sich mit den Analysen beschäftigt, sollten sich Unternehmen mit den zentralen Fragen und zu lösenden Problemen auseinandersetzen. So können basierend auf Prozessmodellen, Datenmodelle aufgebaut und die Auswahl der passenden Algorithmen beschleunigt werden. Zudem lässt sich so abschätzen, ob der zu erwartende Nutzen – wie niedrigere Ausschussreduktion – den Aufwand wirtschaftlich überhaupt lohnt. Das größte Potential von Datenanalysen liegt meist bei prädiktiven und präskriptiven Auswertungen. Das liegt daran, dass der Ausschuss eines Produktes zu einem frühen Zeitpunkt dem Unternehmen weniger Kosten verursacht, als die Aussteuerung eines Erzeugnisses, in das bereits viele Resourcen investiert wurden. Abschließend lässt sich festhalten: Mit dem Grad der Implementation des Datenlebenszyklus steigt auch der Wert der Daten, da sich auf dieser Basis fortgeschrittene Analysen wie prädiktive Analysen in die Prozesse integrieren und und so Kosten sparen lassen.