Fachliteratur per Algorithmus auswerten
Wissensaufbau mit Text-Mining
Viele produzierende Unternehmen investieren längst in Fertigungstechnik, die sich der Vision von cyber-physischen Systemen nähert. Doch das gibt es noch lange nicht von der Stange, sondern muss zum Teil auf Basis aktueller Forschungen adaptiert werden. Diese zeitaufwendige Arbeit wiederum können Text-Mining-Analysen unterstützen. Der Analytics-Spezialist Mayato hat sich mit solchen Modellen kürzlich einen Überblick zum Thema ‚Sensordatenanwendungen in der industriellen Fertigung‘ verschafft – und gibt Einblicke, wie sich Literaturreviews so deutlich beschleunigen lassen.
")
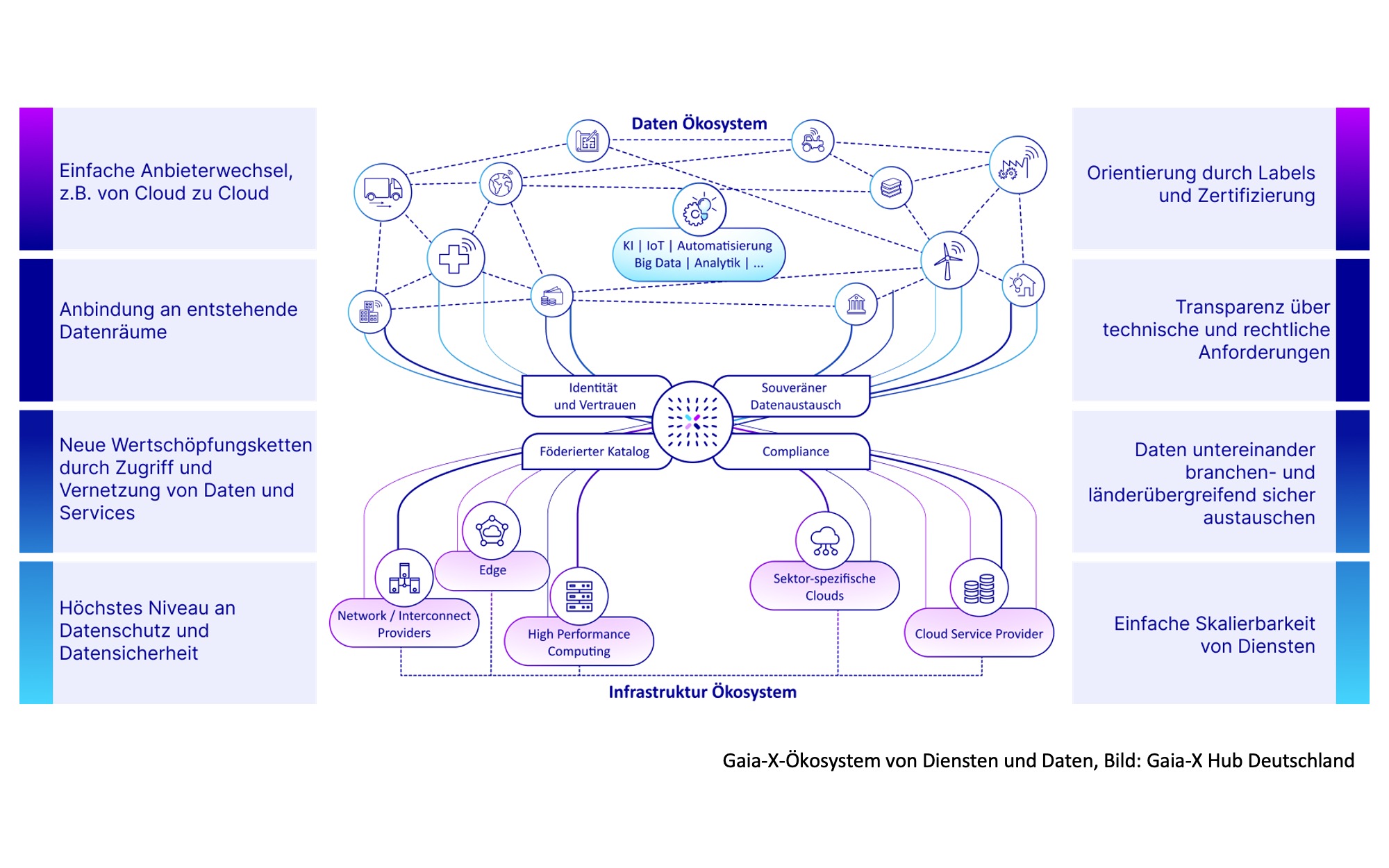
Unstrukturierte Daten aus natürlichsprachlichen Texten machen einen erheblichen Teil der in Unternehmen gespeicherten Informationen aus. Intern archiviert werden beispielsweise Korrespondenzen, Verträge, Berichte oder Studien mit Geschäftsrelevanz. Darüber hinaus sind unzählige Webseiten und Services extern über das Internet abrufbar, welche wertvolle branchenrelevante Informationen in Nachrichten, Produktreviews oder Pressemitteilungen enthalten können. Für die Analyse unstrukturierter Texte mit dem Ziel, Wissen effizient und effektiv aus einem vorliegenden Korpus abzuleiten, bietet Text Mining einige etablierte Methoden an. Mit statistischen Verfahren oder künstlicher Intelligenz wird den Texten dabei eine semantische Struktur verliehen, anhand welcher das Korpus durchsucht, zusammengefasst und beschrieben werden kann. Dadurch wird das Wissen aus den Texten schnell und einfach zugänglich gemacht und kann zudem breiter aufgenommen werden. Und genau darum ging es im vorliegenden Projekt: Anwendungsfälle und Herausforderungen der digitalen Fertigung mit Bezug zu Sensordatenanwendungen zu überblicken und den Experten bei Mayato einen unkomplizierten Zugang zu den in der Forschungsliteratur angebotenen Lösungskonzepten, Architekturen und Verfahren zu verschaffen. Dazu sammelte das Team Forschungsarbeiten aus Journalen wie dem Journal of Manufacturing Systems, dem Journal of Intelligent Manufacturing und dem Journal of Manufacturing Science and Engineering. Anhand eines zuvor entwickelten Analysemodells sollten die unterschiedlichen Quellen strukturiert und synthetisiert werden. Abbildung 1 stellt auf einem abstrakten Detaillevel den grundlegenden Aufbau des Analysemodells dar.
")
Analyseergebnisse
Noch bevor durch das Clustering der Literatursammlung automatisiert eine Struktur verliehen wird, gibt schon die Betrachtung der häufigsten Wörter Aufschlüsse über die wichtigen Themen, Methoden und Begriffe im Korpus. Neben alleinstehenden Wörtern können auch Phrasen aus mehreren Wörtern mit Hilfe künstlicher Intelligenz automatisch identifiziert und daraufhin gezählt werden. Diese Phrasen sind häufig besonders aussagekräftig. Abbildung 2 zeigt die häufigsten Wörter und Phrasen des in dem Anwendungsbeispiel analysierten Korpus. So lässt sich beispielsweise sofort erkennen, dass der Begriff der Echtzeit in diesem Korpus eine sehr wichtige Rolle spielt, oder dass neuronale Netze sehr häufig diskutiert werden. Auf Basis der häufigsten Worte und Phrasen kann ein erster Begriffskatalog für das Forschungsprojekt angelegt werden. Die neunte Ausgabe von Rockwell Automations „State of Smart Manufacturing“ Report liefert Einblicke in Trends und Herausforderungen für Hersteller. Dazu wurden über 1.500 Fertigungsunternehmen befragt, knapp 100 der befragten Unternehmen kommen aus Deutschland. ‣ weiterlesen
KI in Fertigungsbranche vorn
")
Wortwolken visualisieren Zusammenhänge
Weiterhin können vorab bereits die Themen aus einem Topic Model untersucht und bezeichnet werden. Für die Visualisierung bieten sich hier Wortwolken an, wie Abbildung 3 für einige Beispielthemen zeigt. Die Größe der Wörter gibt dabei jeweils deren Wichtigkeit für das jeweilige Thema an. So finden sich unter den Beispielthemen etwa die Themen ‚Messung der Werkzeugabnutzung beim Fräsen mit Vibrationssignalen‘ oder ‚Fehlererkennung in der Montage mit Videodaten‘. Experten können diese Themen mit Hilfe der Visualisierung sehr schnell einordnen und als ein in dem untersuchten Korpus vorhandenes Konzept mit Bezug zu den gegebenen Begriffen identifizieren.
")
Algorithmen übernehmen Synthese
Die Aufgabe des Analysemodelles für die automatisierte Synthese der Literatur ist im ersten Schritt, die in hochdimensionale Vektorrepräsentationen transformatierten Forschungsarbeiten hierarchisch zu clustern. Abbildung 4 zeigt das für das Anwendungsbeispiel aus dem Clustering resultierende Dendrogramm und macht für einige Beispiel-Cluster dessen Teil-Dendrogramm lesbar. Die vertikalen Linien in der Dendrogrammdarstellung zeigen, bei welchem Distanzschwellwert zwei Cluster in eines zusammengeführt wurden, während die horizontalen Linien Aufschluss über die Distanz zwischen den beiden Clustern geben. Für die Bildung der Cluster wird ein Distanzschwellwert gesetzt (vertikale gestrichelte Linie), welcher heuristisch oder empirisch bestimmt werden kann. Beispielsweise das erste oben gezeigte Cluster enthält Arbeiten, welche sich mit der Modellierung und Kompensation thermischer Fehler an Werkzeugmaschinen befassen, während das zweite Beispiel sich ausschließlich mit drahtlosen Sensornetzwerken befasst. Das Dendrogramm kann ebenfalls mit den als Kapitelüberschriften extrahierten Schlüsselwörtern beschriftet werden, wie Abbildung 5 zeigt. Jede Zeile entspricht hier den wichtigsten Schlüsselwörtern für das jeweilige Cluster. So sieht man beispielsweise in der zweiten Zeile, dass für das erste Beispiel oben sehr treffend die Schlüsselwörter ‚Real Time Compensation, CNC Machining Center, Thermal Error, Error Compensation‘ extrahiert wurden. Die Schlüsselwörter sind insgesamt sehr aussagekräftig: Wie das Beispiel zeigt, ist das Analysemodell dazu fähig, kohärente Literaturcluster zu bilden, wie sie ein Mensch unter hohem zeitlichem und kognitivem Aufwand auch bilden könnte. Das Dendrogramm liest sich dabei von oben nach unten wie das Inhaltsverzeichnis eines Buches. Die extrahierten Schlüsselwörter geben – wie Kapitelüberschriften – Aufschluss über die enthaltenen Themen. Es lassen sich leicht thematische Überschneidungen in nebeneinanderliegenden Clustern erkennen. Die Kapitelstruktur eines Literaturreviews kann sich so sehr eng an der Clusterbildung orientieren. Anhand der hierarchischen Struktur des Dendrogramms können die Cluster in Unterkapitel unterteilt werden oder auch in Überkapitel zusammengefasst. Für die weitere Arbeit mit den Forschungsarbeiten können die PDF-Versionen anhand der gefundenen Cluster in eine Ordnerstruktur abgelegt und strukturiert zugänglich gemacht werden. Die für das Literaturreview des Beispiels von Mayato gebildeten Hauptkapitel zeigt Abbildung 6 mit Referenz zu den Clustern im Dendrogramm. Insgesamt bieten die Ergebnisse des Analysemodells eine erhebliche Erleichterung, wenn es darum geht, hunderte oder tausende Forschungsarbeiten zu strukturieren und synthetisieren. Erschöpfende Literaturreviews können hiervon besonders profitieren, da sehr schnell ein strukturierter Überblick über das betrachtete Feld ermöglicht wird. Die Anfertigung des Literaturreviews und das Herauskristallisieren der wissenschaftlichen Erkenntnisse – unterstützt durch die Analyseergebnisse – bleibt schließlich kreative Aufgabe der Forscher. Das Manufacturing Execution System (MES) HYDRA optimiert Produktionsprozesse für Fertigungsunternehmen, um Wettbewerbsvorteile zu erzielen. ‣ weiterlesen
MES-Integrator und 360-Grad-Partner für optimierte Fertigung
")
Fundament für den Wissensaufbau
Literaturreviews sind ein unverzichtbarer Bestandteil von Forschungsprojekten und sie spielen eine wichtige Rolle für den Wissensaufbau in forschenden Unternehmen. Das vorgestellte Analysemodell kann Wissensarbeitern kognitiven Aufwand abnehmen, der sonst in die Analyse, Strukturierung und Synthese von Literatur fließen würde. Es erleichtert Forschern den Umgang mit großen Mengen an Literatur und kann einen wichtigen Beitrag zur Steigerung der Produktivität in der Review-Phase von Projekten leisten. Den Aufbau und die Organisation von Wissen im Unternehmen kann das Analysemodell damit unterstützen und beschleunigen.
")
Ansatz vielfältig übertragbar
Die Anwendungsfälle des Analysemodells sind jedoch nicht alleine auf die Literatursynthese in Forschungsprojekten beschränkt. Überall dort, wo große Mengen unstrukturierter Textdaten vorliegen, die es zu analysieren und zu verstehen gilt, kann das Analysemodell als Werkzeug eingesetzt werden. Bei den analysierten Texten kann es sich sowohl um unternehmensexterne Daten aus dem Web handeln, wie etwa um Foreneinträge oder Tweets über die Produkte des Unternehmens, die es im Interesse der Marketingabteilung zu analysieren gilt, als auch um unternehmensinterne Daten, wie Wartungsberichte für die Maschinen aus der Produktion, deren Analyse den Ingenieuren Verbesserungspotentiale in den Wartungsroutinen für weniger Maschinenstillstände aufzeigen können. Es ist außerdem denkbar, Suchmaschinen für unternehmensinterne Textdaten zu entwickeln, um für gegebene Queries die relevantesten Texte aus dem Unternehmen zurückliefern zu können.