Klasse statt Masse
Die richtigen Daten bereitstellen
Nur weil Daten vorhanden sind, heißt das noch nicht, dass beispielsweise Fehler der Vergangenheit angehören. Es kommt auch darauf an, die Daten, die man zur Verfügung hat, in den richtigen Kontext zu setzen und sie aufzubereiten. Datenmanagement ist gefragt, die Spezialisten dazu noch mehr. Schade ist, dass einmal gefundene Data Scientists bis zu 76 Prozent ihrer Zeit für die Aufbereitung der Datenmengen aufwenden.
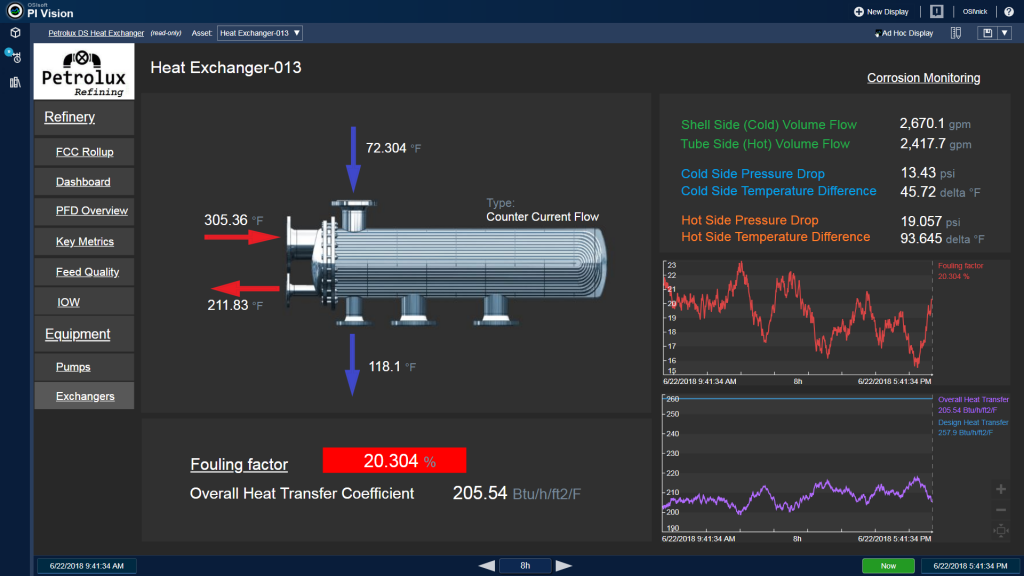
Forscher der Lawrence Livermore National Laboratories (LLNL) beobachteten rasche Schwankungen der elektrischen Last von Sequoia, einem der weltweit leistungsstärksten Supercomputer. Sie standen vor einem Rätsel. Die Schwankungen waren enorm – die Leistung fiel von 9 MW auf wenige hundert Kw – und bescherten dem zuständigen Energieversorger erhebliche Koordinationsprobleme. Die Schwankungen traten vorzugsweise jede Woche zur gleichen Zeit auf. Durch die Untersuchung diverser Datenströme kam man der Ursache des Problems schließlich auf die Spur: die Schwankung hing mit der regulären Wartung der massiven Kühlanlage zusammen. Durch einen sanfteren Anlauf konnten die LLNL ihrem lokalen Stromversorger helfen.
Dieser Sachverhalt wirft ein häufig vernachlässigtes Problem mit Big Data auf. Analysetechniken und Maschinendaten haben großen Einfluss auf die globale Wirtschaft und eröffnen große Chancen für die Informationstechnologie. Marktforschungsinstitute wie A.T. Kearny and Bain gehen davon aus, dass die Umsätze für IoT-Hardware, -Software und -Services schon in wenigen Jahren mehr als 300 Milliarden US-Dollar ausmachen werden. Viele dieser Initiativen könnten jedoch ins Leere laufen, wenn es nicht gelingt, Systeme und Prozesse zu entwickeln, die Menschen den Zugang zu den ‚richtigen‘ Daten eröffnen – akkuraten, relevanten, verständlichen und zeitnahen Daten, die einerseits die notwendige Komplexität aufweisen, aber andererseits von Mitarbeitern und Partnern in der gesamten Wertschöpfungskette einfach zu verstehen sind. Die neunte Ausgabe von Rockwell Automations „State of Smart Manufacturing“ Report liefert Einblicke in Trends und Herausforderungen für Hersteller. Dazu wurden über 1.500 Fertigungsunternehmen befragt, knapp 100 der befragten Unternehmen kommen aus Deutschland. ‣ weiterlesen
KI in Fertigungsbranche vorn
Der richtige Kontext
Die relevanten Daten bereitzustellen bedeutet allerdings nicht nur, Fehler auszuschalten, Lücken zu füllen und redundante Informationen auszuschließen. Eine der größten Herausforderungen besteht darin, die Daten in den richtigen Kontext zu bringen und sie auf diese Weise brauchbar zu machen. Beim LLNL waren beispielsweise alle Daten vorhanden. Sie lagen aber nicht so vor, dass man aus der Datenfülle eine Antwort erhalten hätte können. Daten, die verloren gehen oder ein Schattendasein fristen, stellen ein großes Problem dar. McKinsey & Co. gehen beispielsweise davon aus, dass lediglich ein Prozent der Daten von den etwa 30.000 Sensoren an einer Ölplattform überhaupt gesichtet und für eine Entscheidungsfindung herangezogen werden.
Daten aufbereiten
Ein Tribut, den man für das Datenmanagement zu entrichten hat, ist ist der Zeitaufwand für die Aufbereitung. Data Scientists – die zu den begehrtesten und am häufigsten neu eingestellten Mitarbeitern der heutigen Arbeitswelt gehören – verbringen in der Regel 50 bis 80 Prozent ihrer Arbeitszeit als ‚Datenaufbereiter‘, 76 Prozent von ihnen sind der Meinung, dass dies der unattraktivste Teil ihrer Aufgabe sei. Spreadsheets, Textdateien und diverse andere Werkzeuge kommen dabei zum Einsatz.

Zwei Petabyte am Tag
Eine der großen Hürden ist das Ausmaß der Aufgabe an sich. Das Internet of Things treibt die drei ‚V‘ von Big Data – Volume, Variety and Velocity – ins Extreme. Ein Smart Mining-Projekt kann durchaus zwei Petabyte an Daten in einer 16-Stunden-Schicht generieren. Daten von intelligenten Zählern – ein kritisches Element für die Überwachung des Energieverbrauchs und wichtig für die Verbreitung von Wind- und Solarenergie – könnten schon bald Netflix in den Schatten stellen. Systeme zur Vibrationsanalyse, die kleinste Änderungen in der Signalform auswerten, um vor möglichen Problemen zu warnen, können bis zu 400.000 Signale pro Sekunde aufnehmen. Das Manufacturing Execution System (MES) HYDRA optimiert Produktionsprozesse für Fertigungsunternehmen, um Wettbewerbsvorteile zu erzielen. ‣ weiterlesen

MES-Integrator und 360-Grad-Partner für optimierte Fertigung
Unterschiedliche Formate
Darüber hinaus wird die Datenvielfalt zur Herausforderung. Die Hersteller von Geräten implementieren ein breites Spektrum von Standards und Datenformaten, weit mehr als die IT-Industrie selbst. Beispielsweise könnte ein Windpark Daten von mehr als 300.000 Signalen oder Datenquellen aktiv akquirieren, die in unterschiedlichen Formaten ankommen. Einige dieser Abweichungen ist den restriktiven Betriebs- und Sicherheitsstandards geschuldet, ohne die es in vielen Branchen nicht geht. Auch das Alter der jeweiligen Anlagen spielt eine Rolle. Ein Teil der heute noch in der Stromerzeugung und in Raffinerien betriebenen Anlagen wurde vor Jahrzehnten installiert und nach Spezifikationen und Standards gebaut, die bereits weitgehend vom Markt verschwunden sind. Unternehmen müssen aber immer noch mit solchen Anlagen kommunizieren können. Jedes System, das man installiert, muss daher eine Vielzahl von ‚Dialekten‘ beherrschen.
Womit beginnnen?
Wie bei den meisten großen technologischen Initiativen sollten auch Unternehmen zunächst ihre Ziele festlegen. Wollen Sie ein aktuelles Problem wie ungeplante Ausfallzeiten angehen, entwickeln Sie neue Dienstleistungen oder wollen Sie Ihre Fertigungslinien mit prädiktiver Wartung und Diagnose ausstatten? Werden die Daten in Echtzeit benötigt, um die Qualität einer Chemieproduktion zu überwachen, oder sammeln Sie im Wesentlichen Daten, die mit anderen Quellen kombiniert und über mehrere Wochen oder Monate hinweg in der Cloud analysiert werden? Die Forderung nach minimalen Latenzzeiten wird signifikante Auswirkungen auf die Art und Weise haben, wie Unternehmen ihre Daten sammeln und auswerten.