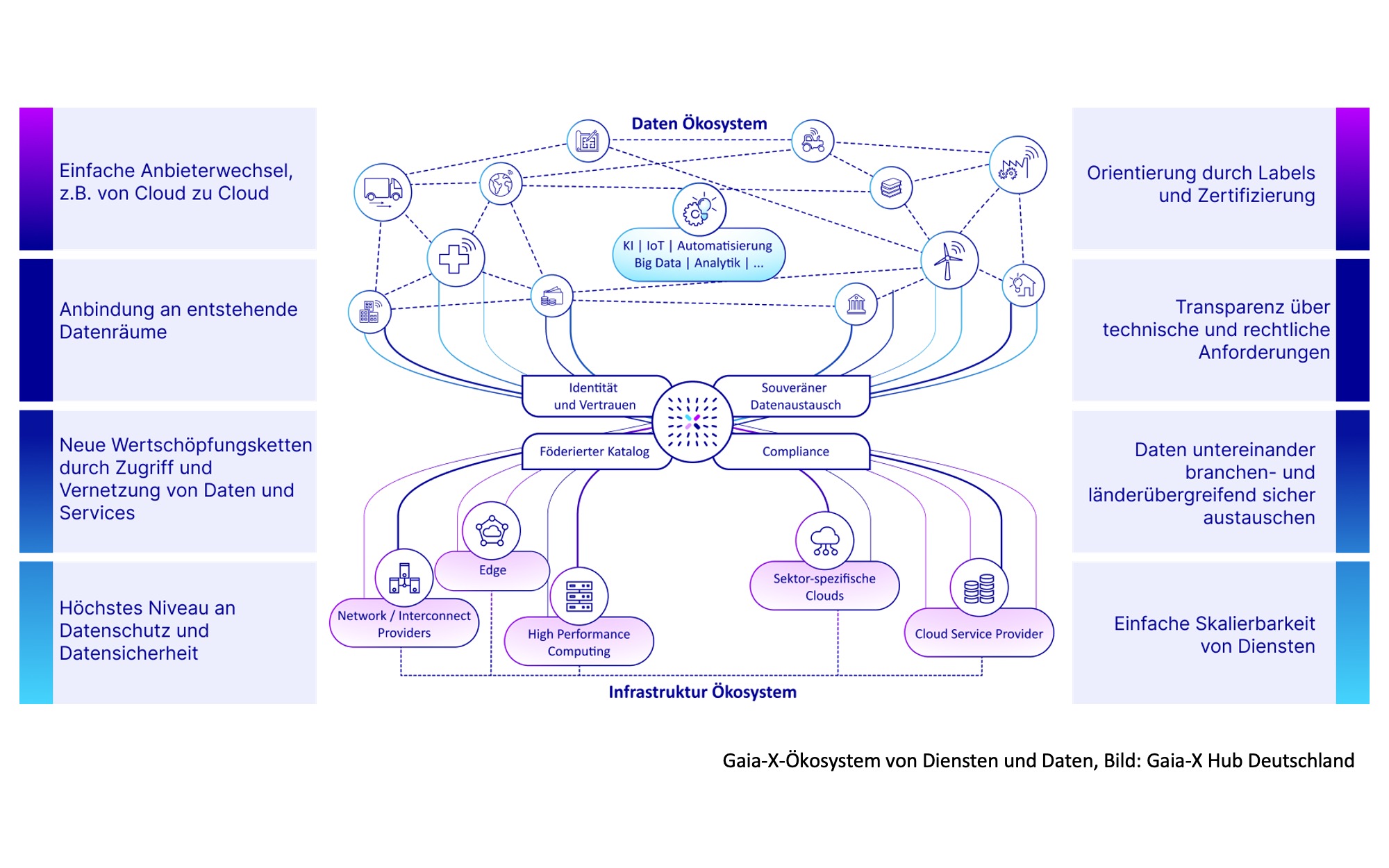
Von semantischen Netzen und Data Lakes
Investieren in verknüpfte Datensilos
Was im Datensilo abgelegt ist, wird meist selten bis gar nicht genutzt. Das bedeutetet jedoch nicht, dass diese Daten keinen Nutzen hätten, im Gegenteil. Um Informationen aus dem gesamten Datenbestand zu erhalten, müssen die einzelnen Silos verknüpft werden. Das funktioniert über Ansätze wie Product Lifecycle Management oder die Ausprägung semantischer Netze sowie Technologien wie den Data Lake.

Starke globale Konkurrenz kann besonders bei Anbietern von komplexen Produkten wie im Automobilbau zu Effizienzdruck führen. Ein entscheidender Faktor für die Marktposition ist ein sichtenbasierter Zugriff auf die eigenen Daten sowie die Möglichkeit, daraus Wissen abzuleiten. Beispielsweise werden bei der Entwicklungsabsicherung im Automobilbereich virtuelle und reale Welt durch hybride Validierungsformen (Mixed Validation) verbunden: Ein Teil der Funktionsprüfung findet in Form einer virtuellen Simulation, der andere Teil am realen Prüfstand statt. Datenkomplexität und -heterogenität sowie die Erzielung einer Datendurchgängigkeit durch Verknüpfung von Datensilos sind dabei die größten Herausforderungen. Auch fernab dieses Beispiels gilt es, Datensilos zu verknüpfen und flexible Sichten für unterschiedliche Rollen in kurzer Zeit zur Verfügung zu stellen. Insbesondere die Reduzierung der Markteinführungszeiten durch Virtualisierung erfordert performante IT-Ansätze, die auch hochkomplexe Datenaggregation skalierbar realisieren können. Auch bei der zunehmenden Verbreitung von IoT-Technologien werden verstärkt Daten aus unterschiedlichen Quelles zusammengeführt werden müssen, um diese dann wertschöpfend – beispielsweise für Predictive Maintenance – mit Hilfe von maschinellem Lernen zu nutzen.
Grundlegende Konzepte
Zum Verknüpfen von Datensilos existieren bereits Softwaresysteme, die jedoch unterschiedliche Lösungswege einschlagen: Der klassische Ansatz setzt ein monolithisches System voraus, das die Entstehung von Datensilos mit Hilfe von Product-Lifecycle-Management-Werkzeugen verhindern soll. Begrenzte Flexibilität, Lock-In-Effekte, eine hohe Softwarekomplexität sowie Trägheit beim Rollout sind jedoch Nachteile dieses Ansatzes. Eine Alternative bieten semantische Netze: Mit ihnen können Zusammenhänge in Daten abgebildet und somit Datensilos überbrückt werden. Durch Modellierung von Datenzusammenhängen entsteht ein Gesamtbild. Voraussetzung dafür ist Wissen über die Daten und ihre Zusammenhänge sowie eine Use-Case-Fokussierung. Um ein semantisches Datennetz zu realisieren, müssen jedoch Verknüpfungsregeln definiert werden. Die neunte Ausgabe von Rockwell Automations „State of Smart Manufacturing“ Report liefert Einblicke in Trends und Herausforderungen für Hersteller. Dazu wurden über 1.500 Fertigungsunternehmen befragt, knapp 100 der befragten Unternehmen kommen aus Deutschland. ‣ weiterlesen

KI in Fertigungsbranche vorn
Ergänzung durch den Workflow
Workflowbasierte Verfahren können semantische Netze ergänzen. Ausgangspunkt für solche Lösungen ist beispielsweise der Fertigungsprozess, der als Treiber für den Datenbedarf und die Verknüpfungen dient. Der Nutzer wird durch den Prozess geführt und bekommt gleichzeitig die situativ richtigen Daten präsentiert. Dem gegenüber steht jedoch ein hoher Aufwand beim Implementieren der Workflows, da diese – inklusive vorzusehender Datenverknüpfungen – für jeden Prozess einzeln zu modellieren und zu pflegen sind.
Technologische Ansätze
Die unterschiedlichen Lösungswege gehen mit einem Pool technologischer Ansätzen einher. Aktuell werden verstärkt drei davon eingesetzt: Graphbasierte Metadatenmodelle, Peer-to-Peer-Verknüpfung durch offene Standards und Data Lakes. Graphbasierte Metadatenmodelle werden zur Realisierung semantischer Datennetze genutzt. Das Datennetz ist entlang seiner Kanten von Knoten zu Knoten modellier- sowie abfragbar und somit flexibel anpassbar. Abfragelogiken können einfach umgesetzt werden. Durch die Flexibilität graphbasierter Metadatenmodelle können gerade Anwendungen profitieren, die eine Verknüpfung von Daten über mehrere Produktlebenszyklusphasen hinweg erfordern. P2P-Verknüpfungen mit offenen Standards empfehlen sich besonders bei kleinen Vernetzungsprojekten, da keine Datenvernetzungsplattform bereitgestellt werden muss. Außerdem konzentriert sich die Arbeit auf die – gegebenfalls vom Systemanbieter bereits implementierte – Bereitstellung von Schnittstellen zwischen je zwei Datensilos. Für große Datenvernetzungsprojekte ist eine P2P-Lösung jedoch nicht geeigent, da bei steigender Anzahl der zu verknüpfenden Datensilos die Kosten steigen und Flexibilität sowie Datenqualität sinken.
Das Konzept Data Lake
Data Lakes wiederum können Daten aus einer Vielzahl an Quellen beinhalten. Sie sind kein monolithisches IT-System, sondern ein Konzept für den Datenzugriff. Dabei werden die Ursprungsformate der abgelegten Daten nicht verändert, sondern nur eine standardisierte Schnittstelle bereitgestellt. Die kontextspezifische Gruppierung der Daten (Data Marts) erfolgt regelbasiert. Die Datenaggregation wird aus Abfragesicht verborgen, wodurch die Komplexität der Datenzusammenführung bei der Formulierung der Abfrage zu vernachlässigen ist. Somit stellen Data Lakes komfortable Lösungen dar, um standardisierten Zugriff auf den Datenbestand zu erhalten und insbesondere Data-Analytics-Anwendungen bestmöglich zu versorgen. Ihr Nachteil ist jedoch der Aufwand für die Inbetriebnahme. Daten müssen zuerst in den Data Lake kopiert werden. Zudem müssen Prozesse und IT so gestaltet werden, dass möglichst alle Daten in den Data Lake fließen. Abschließend ist zu bedenken, dass der Data Lake aufgrund seines umfassenden Datenbestandes ein beliebtes Angriffsziel für Hacker ist. Der Thin[gk]athon, veranstaltet vom Smart Systems Hub, vereint kollaborative Intelligenz und Industrie-Expertise, um in einem dreitägigen Hackathon innovative Lösungsansätze für komplexe Fragestellungen zu generieren. ‣ weiterlesen

Innovationstreiber Thin[gk]athon: Kollaborative Intelligenz trifft auf Industrie-Expertise
Maschinelles Lernen
Der Aufwand zur Erstellung und Pflege von Datenverknüpfungen ist hoch. Maschinelles Lernen kann dabei helfen, ihn zu reduzieren, indem neue Zusammenhänge automatisch entdeckt und bestehende gepflegt werden. Durch die Kombination unterschiedlicher Lernverfahren könnten Datenvernetzungsplattformen die benötigten Informationen in Zukunft beispielsweise nutzer- und prozessspezifisch bereitstellen. .
Anforderungen im Engineering
Continuous Development und Agilität werden den realen Effizienzdruck weiter erhöhen. Multidisziplinäre Teams müssen immer schneller auf neue Randbedingungen reagieren und sich auf neue Geschäftsmodelle einstellen. Dazu werden langfristig erfasste Daten übergreifend verknüpft und für einen Digital Master oder einen Digital Twin genutzt. Diese werden zu lebendigen Datenreferenzen für den gesamten Produktlebenszyklus. Datenvernetzung muss schnell und wartungsarm funktionieren. Das Engineering der Zukunft erfordert daher mutige Investitionen und Forschung, um effiziente Datenvernetzungsplattformen als wichtiges Basiselement für die flexible, qualitative Vernetzung von unterschiedlichsten Datenkategorien und -quellen in der Praxis zu etablieren.